模型評分服務使用說明
概述
本專案流程為評估語言模型執行四大任務(公文、新聞稿、民眾陳情、模擬問答)的能力。評估方式為,使用另一語言模型作為裁判,針對模型生成的內容進行評分。專案執行位置: https://jenkins.genai.nchc.org.tw/job/03-model-evaluation/
前置需求
GitLab 專案 (Repository)
-
請先自行建立專案
-
申請存取令牌(Access tokens)
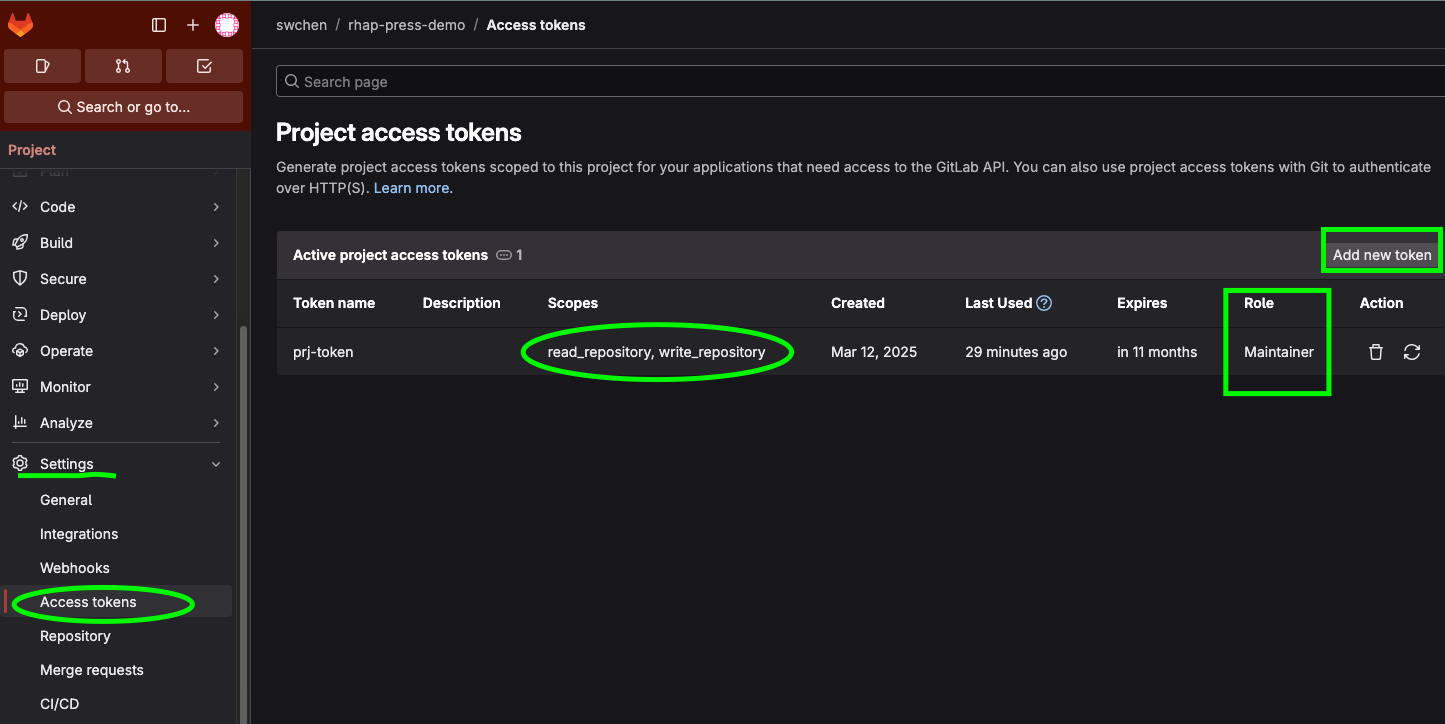
(1) 申請方式:進入欲使用的專案 -> Settings -> Access tokens -> Add new token
(2) Scopes 選擇 read_repository, write_repository
(3) Role 選擇 Maintainer 或 Owner
(4) 存取令牌申請完成後,請務必存在安全的地方,離開頁面後便無法再取得
-
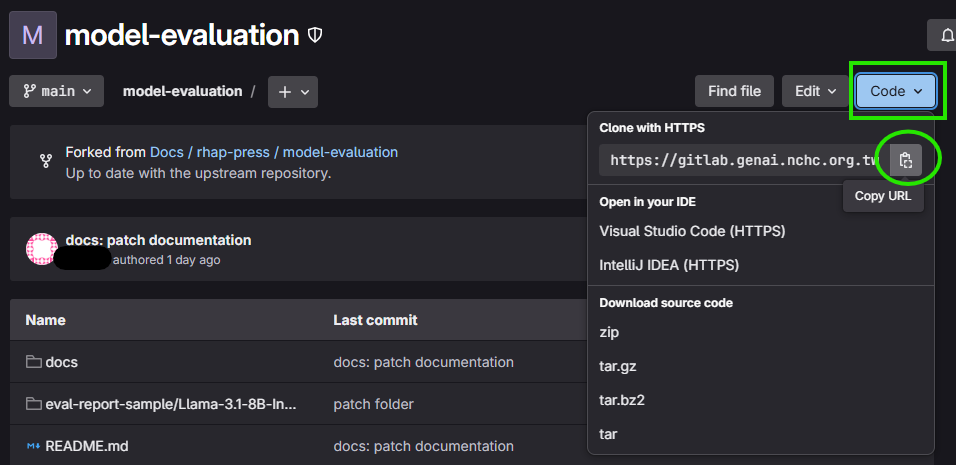
取得專案 URL
GIT_REPO_URL
-
建立儲存評估結果的目錄
GIT_REPORT_DIRgit clone <GIT_REPO_URL>
cd <git_repo_dir>
mkdir <GIT_REPORT_DIR> # 建立儲存結果的docs/image.png目錄
cd <GIT_REPORT_DIR>
touch .gitkeep # 建立佔位檔案
git push origin main # 推回你的遠端專案
模型 API
模型評分流程總共會使用到2個語言模型:1. 欲評估的模型 GEN_MODEL 2. 裁判模型 JUDGE_MODEL。
參數說明
基本設定
| 名稱 | 類型 | 說明 |
|---|---|---|
GIT_REPO_URL | 字串 | 『必填』請填入自行建立的 Git repository URL (例: https://gitlab.genai.nchc.org.tw/swchen/rhap-press-demo.git) |
GIT_REPO_TOKEN | 密碼 | Git repository 的存取令牌 (Access token); 請參考前置需求(需有 Maintainer/Owner 權限; 例: glpat-xxx) |
服務專屬設定
模型相關參數
| 名稱 | 類型 | 說明 |
|---|---|---|
GEN_MODEL | 字串 | 『必填』產生回答的模型,亦即你想要評估的模型。可選 Medusa 或其他公開模型(gpt-4o-mini, gpt-4o) Medusa 支援的模型列表 medusa-models.md |
GEN_API_URL | 字串 | 『必填』提供 GEN_MODEL 模型服務的 URL範例:Medusa: https://medusa-poc.genai.nchc.org.tw/v1 ; OpenAI: https://api.openai.com/v1 |
GEN_API_KEY | 密碼 | 『必填』使用 GEN_API_URL 的 API KEY |
JUDGE_MODEL | 字串 | 『必填』選擇進行評分的裁判模型。可選 Medusa 或其他公開模型(gpt-4o-mini, gpt-4o) Medusa 支援的模型列表: medusa-models.md 建議使用能力較強的模型,如:gpt-4o, Llama-3.3-70B-Instruct |
JUDGE_API_URL | 字串 | 『必填』提供 JUDGE_MODEL 模型服務的 URL範例:Medusa: https://medusa-poc.genai.nchc.org.tw/v1 ; OpenAI: https://api.openai.com/v1 |
JUDGE_API_KEY | 密碼 | 『必填』使用 JUDGE_API_URL 的 API KEY |
流程參數
| 名稱 | 類型 | 說明 |
|---|---|---|
GIT_REPORT_DIR | 字串 | 評分結果輸出路徑(相對於根目錄,如:eval_report) |
EVAL_ITER | 正整數 | 重複評分次數 (max=30)。由於語言模型輸出有一定的隨機性,為求評分的可靠性,可選擇重複評分。最終結果為去除離群值後取平均。EVAL_ITER 越大,得到的結果越可靠,但耗時越長, 模型調用次數越多 |
進階設定
| 名稱 | 類型 | 說明 |
|---|---|---|
MAX_NEW_TOKENS | 正整數 | 預設 1024 |
BATCH_SIZE | 正整數 | 預設 25 |
硬體設定
| 名稱 | 類型 | 說明 |
|---|---|---|
GPU_COUNTS | 下拉選單 | GPU 數量 1/2/4/8 |
使用步驟
操作流程

輸出結果
訓練完成後會自動上傳至指定倉庫,結構如下:
<GIT_REPORT_DIR>/
└── <GEN_MODEL>/
└── <timestamp>/
├── od/ # 四大任務詳細結果請見對應的資料夾
├── petition/
├── press/
├── qa/
└── overall_report.csv # 四大任務總體分數
常見問題
Q: 為什麼流程開始沒多久就失敗?
A: 請檢查是否有填入你自己的GIT_REPO_URL,並且務必填入正確的GIT_REPO_TOKEN。最後請確認GIT_REPORT_DIR存在你的專案。
Q: 已經創建空的目錄,但 git 無��法追縱空目錄
A: 請在空白目錄裡建立一個佔位檔案 .gitkeep
Q: 為什麼我的 Report 裡某些項目的分數是 null?
A: 由於本專案使用語言模型進行評分任務,語言模型的輸出有一定隨機性。根據模型的能力不同,有些模型輸出無法符合提示要求地輸出格式,因此造成解析失敗。解析失敗的項目會以 null 填入,並且在後續計算平均分數時自動排除。選擇能力較好的模型進行評分可以有效排除此疑慮。
Q: EVAL_ITER 要設多少?
A: 由於語言模型輸出有一定的隨機性,為求評分的可靠性,可選擇重複評分。最終結果為去除離群值後取平均。EVAL_ITER 越大,得到的結果越可靠,但耗時越長,模型調用次數越高。請自行權衡效益及成本。
Q: 我應該怎麼解讀輸出結果?
A: 裁判模型會從兩個面向對模型輸出進行評估: MatchPoint(文本匹配度)和 TextFormat(文本格式)。前者著重模型是否針對使用者的 Prompt 切題回應、是否誤植 Prompt 提到的關鍵字(如:專有名詞);後者注重模型生成的文本是否符合任務文類要求的格式、文體。
overall_report.csv裡所呈現的四大任務分數為綜合考量兩面向後的平均分數(權重相同),如果你在設置參數時EVAL_ITER大於 1,分數會進行去除離群值後再取平均,以得到更嚴謹的評分結果。- 每個任務資料夾內有詳細的評估結果(.json),記錄題庫內每一題的問題、參考答案、
GEN_MODEL生成的文本、JUDGE_MODEL的給分意見、MatchPoint & TextFormat 詳細分數。要注意的是,如果你在設置參數時EVAL_ITER大於 1,僅取第一次的詳��細評估結果輸出。